
深度学习-多标签图像分类
多标签图像分类论文学习
CSRA(ICCV2021)
Residual Attention: A Simple but Effective Method for Multi-Label Recognition
灵感来源

主要贡献
- 提出一个简单但是有效的方式来提升预训练模型(不需要进一步的训练)
- 提出CSRA模块(在四个多标签数据集中取得优异结果)
- 对于主要的注意力模型的一个直观地可视化
总体架构

大致流程:图片通过CNN Backbone 得到特征图,再通过1×1的卷积,将特征图变为C×h×w,C代表的是类的个数,然后将特征送入多头CSRA模块,得到输出y` ,将所有的 y相加,得到最终的输出。
Residual attention

举例:X: h×w×d(7×7×2048),代表的是$x_1,x_2,x_3…x_{49},其中x_{i}∈R^{2048}$,经过1×1的卷积部分,得到$m_1,m_2,…m_{i},其中m_i代表的是第i类$,
Average pooling
平均池化:$g=\sum_{k=1}^{49}x_k$
Spatial pooling
空间池化: $s_j^i=\frac{exp(Tx_j^Tm_i)}{ \sum_{k=1}^{49}exp(Tx_k^Tm_i)}$,并且$\sum_{k=1}^{49}s_k^i=1$
其中i表示第i个类,j表示第j个空间位置,T是一个大于0的控制参数
可以把$s_j^i$ 看作第 i 类出现在位置 j 的概率
$a^i=\sum_{k=1}^{49}s_k^ix_k$
解释CSRA模块
$y^i=m_i^Tg+λm_i^Ta^i$=$\frac{1}{49}\sum_{k=1}^{49}x_k^Tm_i+λ\sum_{k=1}^{49}\frac{exp(Tx_k^Tm_i)}{ \sum_{l=1}^{49}exp(Tx_l^Tm_i)}x_k^Tm_i$
当 T 趋近于 ∞,加号后面的部分就变为$λmax(x_1^Tm_i,..,x_{49}^Tm_i)$,相当于代码中的λ×y_max。
更具体地说:

多头注意力:由于T的值很难调整,所以采用多头注意力机制,T值虽然不同,但是λ都一样。
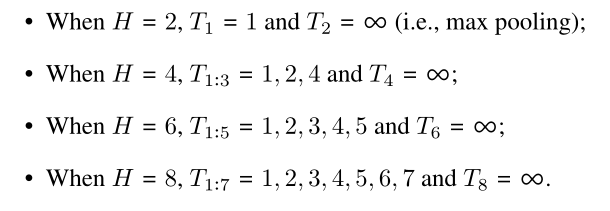
最大下采样的作用
y_max是在每个类别的所有空间位置中找到最大值,所以,它可以被看作是一种特定于类的注意力机制。作者说可以把它推测为将注意力集中在不同对象类别在不同位置的分类分数上。直观地说,这种注意力机制对于多标签识别非常有用,特别是当对象来自许多类别且大小不同时。
